PostgreSQL 9.0 Memory & Processes
Published on Mon, Apr 25, 2011
Going forward with PostgreSQL Architecture, here I would be discussing about the utility process and memory with informative links. Many of the commiters have already documented insightfully about the process and memory, links provided here for those. Modest presentation from my end about the PostgreSQL Utility Process.
Every PostgreSQL Instance startup, there will be a set of utilty process(including mandatory and optional process) and memory. Two mandatory process (BGWRITER and WAL Writer) and four optional process (Autovacuum launcher,stats collector,syslogger, and Archiver). You can check it out with the command ‘ps -ef | grep postgres’ given below in figure 10.1.
Figure 10.1

Overview of the Process and memory.
Figure 10.2
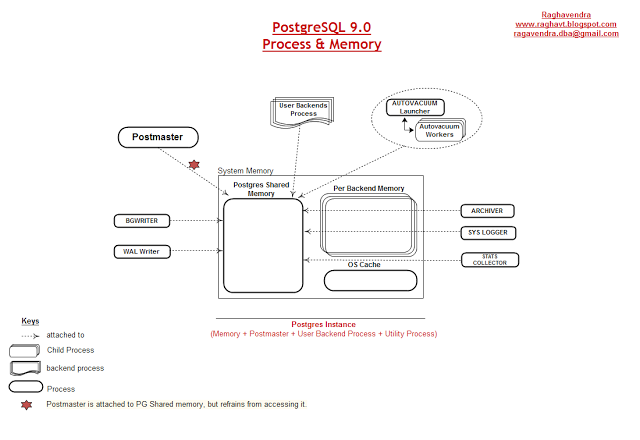
Above figure 10.2 shows the processes attached to the PostgreSQL Shared memory.
BGWriter/Writer Process:
BGWRITER or WRITER process is a mandotary process.
All PostgreSQL server process reads data from disk and moves them into Shared Buffer Pool. Shared Buffer pool uses ARC algorithm or LRU(least-recently used) mechanism to select the page it evicts from the pool. BGWRITER spends much of its time sleeping, but every time it wakes, it searches through the shared buffer pool looking for modified pages. After each search, the BGWRITER chooses some number of modified pages, writes them to disk, and evicts those pages from the shared buffer pool. BGWRITER process can be controled with three parameters BGWRITER_DELAY,BGWRITER_LRU_PERCENT and BGWRITER_LRU_MAXPAGES.
http://www.enterprisedb.com/docs/en/9.0/pg/kernel-resources.html http://www.enterprisedb.com/docs/en/8.4/pg/runtime-config-resource.html
WAL Writer Process:
WAL writer process is a mandatory process.
WAL writer process writes and fsync WAL at convenient Intervals. WAL buffers holds the changes made to the database in the transaction logs, in order to guarantee transaction security. WAL buffers are written out to the disk at every transaction commit, as WAL writer process is responsible to write on to the disk. WAL_WRITER_DELAY parameter for invoking the WAL Writer Process, however there are other parameters which also keeps the WAL Writer busy. Follow below link.
http://www.enterprisedb.com/docs/en/8.4/pg/wal-configuration.html
Stats Collector Process:
Stats collecotr process is optional process, default is ON.
Stats collector process will collect the information about the server activity. It count number of access to the tables and indexes in both disk-block and individual row items. It also tracks the total number of rows in each table, and information about VACUUM and ANALYZE actions for each table. Collection of statistics adds some overhead to query execution, whether to collect or not collect information. Some of the parameter in the postgresql.conf file will control the collection activity of the stats collector process. Following link will brief more about the stats collector process and its related parameters.
http://www.enterprisedb.com/docs/en/9.0/pg/monitoring-stats.html
Autovacuum Launcher Process:
Autovacuuming is a optional Process, default is ON.
For automating the execution of VACUUM and ANALYZE command, Autovacuum Launcher is a daemon process consists of multiple processes called autovacuum workers. Autovacuum launcher is a charge of starting autovacuum worker processes for all databases. Launcher will distribute the work across time, attempting to start one worker on each database for every interval, set by the parameter autovacuum_naptime. One worker will be launched for each database, set by the parameter autovacuum_max_workers. Each worker process will check each table within its database and execute VACUUM or ANALYZE as needed. Following will breif about the AUTOVACUUM LAUNCHER PROCESS parameters.
http://www.enterprisedb.com/docs/en/8.4/pg/runtime-config-autovacuum.html
Syslogger Process / Logger Process :
Figure 10.3
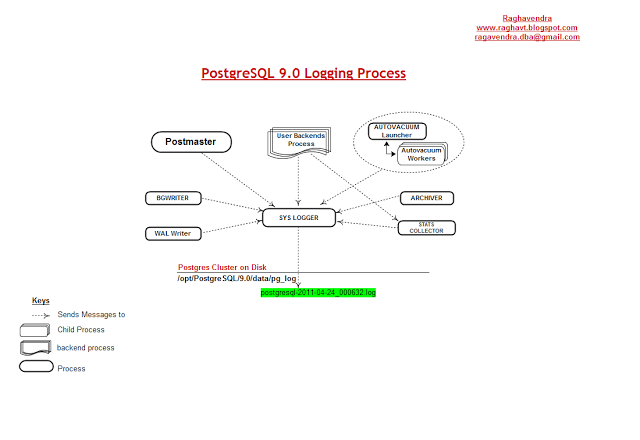
Logging is an optional process, default is OFF.
As per the figure 10.3, it is clearly understood that all the utility process + User backends + Postmaster Daemon attached to syslogger process for logging the information about their activities. Every process information is logged under $PGDATA/pg_log with the file .log.
Note: If the data directory is created with INITDB command, then there wont be pg_log directory under it. Explicit creation is needed.
Debugging more on the process information will cause overhead on the Server. Minimul tunning is always recommended, however, increasing the debug level when required. Link below will brief on logging parameters.
http://www.enterprisedb.com/docs/en/8.4/pg/runtime-config-logging.html
Archiver Process:
Figure 10.4
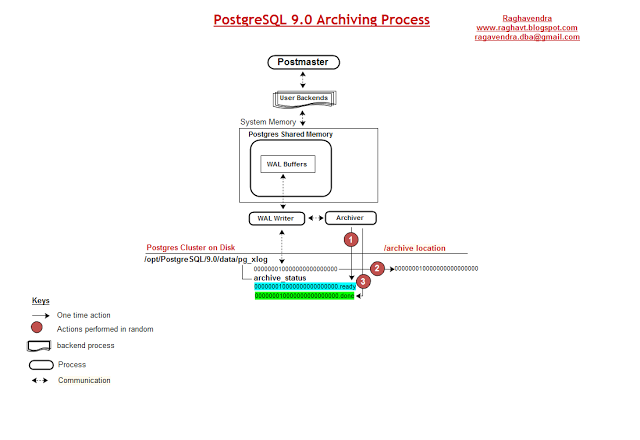
Achiver process is optional process, default is OFF.
Above Figure 10.4 is made from my observation on the Archiving process in PostgreSQL. Setting up the database in Archive mode means, to capture the WAL data of each segment file once it is filled, and save that data somewhere before the segment file is recycled for reuse.
Diagrammatical explination on Numbering tags.
-
On Database Archivelog mode, once the WAL data is filled in the WAL Segment, that filled segment named file is created under $PGDATA/pg_xlog/archive_status by the WAL Writer naming the file as “.ready”. File naming will be “segment-filename.ready”.
-
Archiver Process triggers on finding the files which are in “.ready” state created by the WAL Writer process. Archiver process picks the ‘segment-file_number’ of .ready file and copies the file from $PGDATA/pg_xlog location to its concerned Archive destination given in ‘archive_command’ parameter(postgresql.conf).
-
On successful completion of copy from source to destination, archiver process renames the “segment-filename.ready” to “segment-filename.done”. This completes the archiving process.
It is understood that, if any files named “segement-filename.ready” found in $PGDATA/pg_xlog/archive_status are the pending files still to be copied to Archive destination.
For more information on parameters and Archiving, see the below link. http://www.enterprisedb.com/docs/en/9.0/pg/continuous-archiving.html
Please do post your comments/suggestion on this article, they would be greatly appreciated.
Regards
Raghav